
At Levels.fyi, we're always looking for ways to optimize our platform while delivering the best possible experience to our users. One key aspect of this is managing our cloud infrastructure efficiently. In this post, we'll go over some of our key decisions to minimize cloud costs without compromising on performance or reliability.
Where's the Money Going?
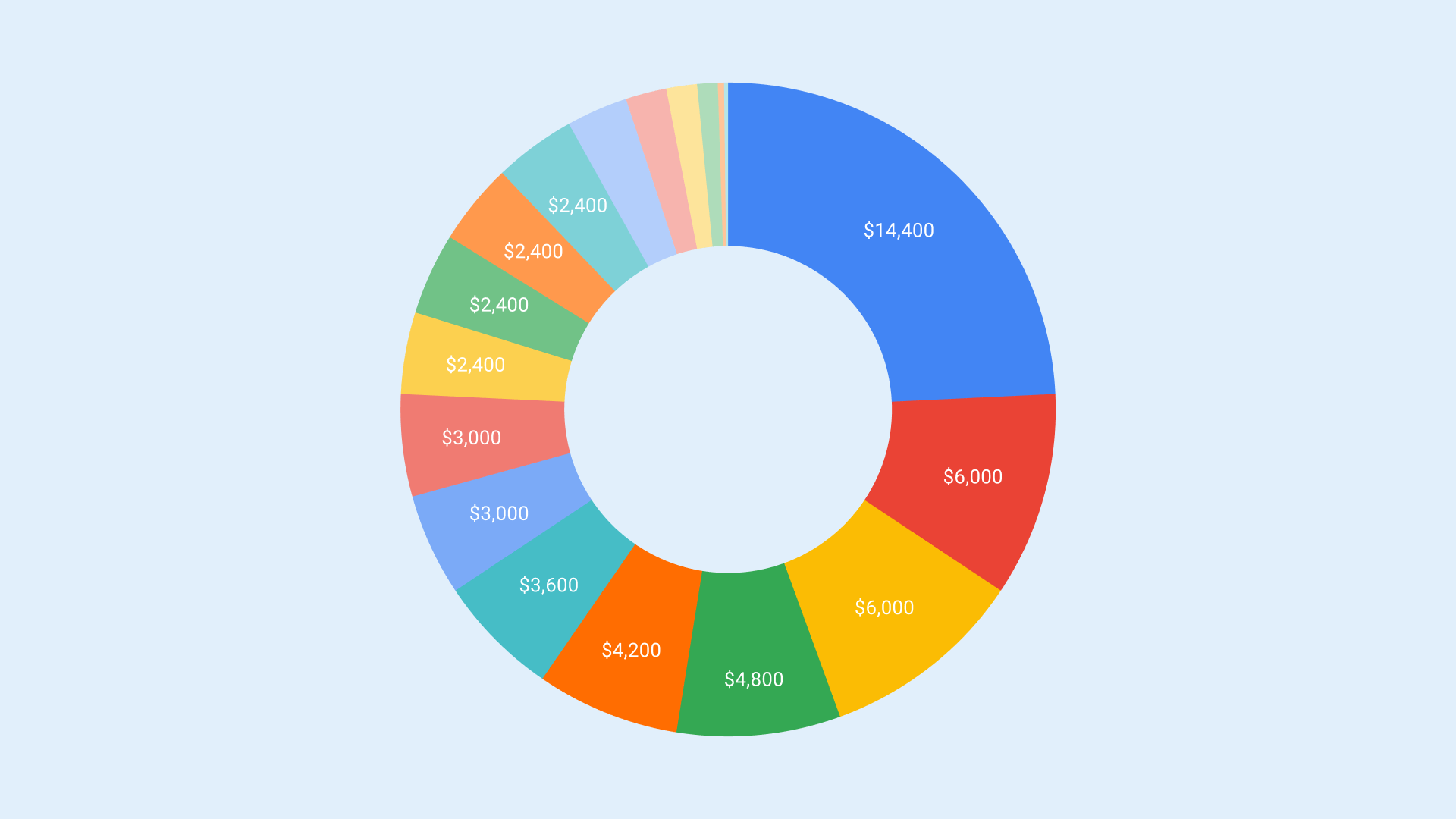
Before we could start slashing costs, we needed to understand where our cloud expenses were coming from. We fired up the AWS Cost Explorer and dove deep into the data. Looking through the console was like an inverted treasure hunt. Instead of looking for gold, we were looking for savings hiding in plain sight.
Over the last 12 months, we served over 650 million pages to more than 26 million unique visitors. Notably, roughly one-fourth of our expenses were attributed to CloudFront.

Unused EC2 Instances
The easiest way to cut costs? Turn off resources you're not using! We discovered a few EC2 instances that were temporarily created for employees to access internal resources securely. Since they were no longer needed, we bid them farewell, along with their associated EBS volumes.
We also utilize other techniques like reserving instances & group buying with Pump, which have proven to be really effective for our use case! Just by using their service were able to cut down roughly $700/m on EC2 & ECS.

The Case of the Mysterious ElastiCache
Next up, we found an ElastiCache instance that wasn't referenced in any of our backend services. We couldn't just remove it without investigating further, so we monitored its CPU usage and bytes I/O. Despite seeing some activity, we had a hunch it wasn't being used as intended. We connected to the instance and ran the DBSIZE and INFO commands to check metrics like connected_clients and total_commands_processed to confirm that instance was indeed not being used.
Upon further investigation, we found out that the CPU and bytes I/O activity was due to a backup process. So after backing it up one last time (just in case!), we bid farewell to the lonely ElastiCache instance.

S3 Historical Data
Our S3 buckets were filled with terabytes of historical job data, and it was growing fast! Since most of this data wasn't actively used, we decided to set a lifecycle policy to move older files to Glacier Deep Archive storage class, which is extremely cheap.
But wait! We had to be careful. Our S3 listeners would add events to SQS whenever a new file was created, and changing the storage class would trigger this process. To avoid overwhelming our backend with terabytes of historical data, we temporarily removed the listeners, migrated the data, and then added the listeners back. Phew! Crisis averted!

ECS Autoscaling
Our frontend services, hosted on AWS Fargate instances, were running on multiple instances even during low-traffic periods. The autoscaling rules were set up when our traffic patterns were different, and now they were overkill.
We fine-tuned the autoscaling configuration to match our current needs, ensuring we had just the right number of instances to handle the load. No more over-provisioning for us!

Upgrading RDS & Lambda
We discovered that our RDS instances were running on t3 processors and using gp2 disks. After careful planning and backups, we migrated them to t4g processors and gp3 disks during a low-traffic window. Not only did this cut costs, but it also gave our databases a performance boost!
On AWS, switching to ARM instances can be an effective low-cost way to reduce significant costs. Hence we carefully migrated to arm64 (ensuring all dependencies are compatible), which resulted in better cost and faster performance.

Tidying Up - ECR, CW & More
We implemented a lifecycle rule in ECR to keep the last 25 versions of our Docker images and automatically purge the rest. We also adjusted the retention time for CloudWatch logs, removing unnecessary logs and saving on storage costs.
Finally, we double-checked our ELBs and NATs to ensure we weren't paying for anything we weren't using. Better safe than sorry!

Wrapping Up
We're always looking for new ways to optimize our cloud infrastructure. By implementing the above changes, we’re now saving ~15% of our cloud spend. Next on our list of optimizations is moving from CloudFront to CloudFlare for a more cost-effective CDN solution.

Managing cloud costs is an ongoing process that requires careful planning, monitoring, and a willingness to adapt. By understanding our cost breakdown, identifying areas for optimization, and making smart decisions, we've been able to slash our cloud bills without sacrificing performance or reliability.

We hope our journey has inspired you to take a closer look at your own cloud infrastructure and find ways to optimize costs. Remember, every dollar saved is a dollar that can be invested back into building an even better product for your users!
Happy cost-cutting!
Interested in reading more? Check out how we optimized our search using Postgres: https://www.levels.fyi/blog/scalable-search-with-postgres.html